
Agentic Retrieval-augmented generation
Large language models (LLMs) provide sophisticated, generalized responses to input queries, but many businesses struggle to harness their full potential. The core challenge is that LLMs are trained on broad datasets, lacking the specific context required to understand unique business operations and processes.
Melting Face bridges this gap with its retrieval-augmented generation (RAG) technology, enabling businesses to customize any LLM for their needs. By building a document library of contextualized, business-specific information, Melting Face empowers LLMs to deliver automated responses and actions tailored to your unique requirements and customer expectations.
This personalized approach allows you to automate and scale processes traditionally reliant on human effort, reducing operational overhead while boosting efficiency and customer satisfaction.

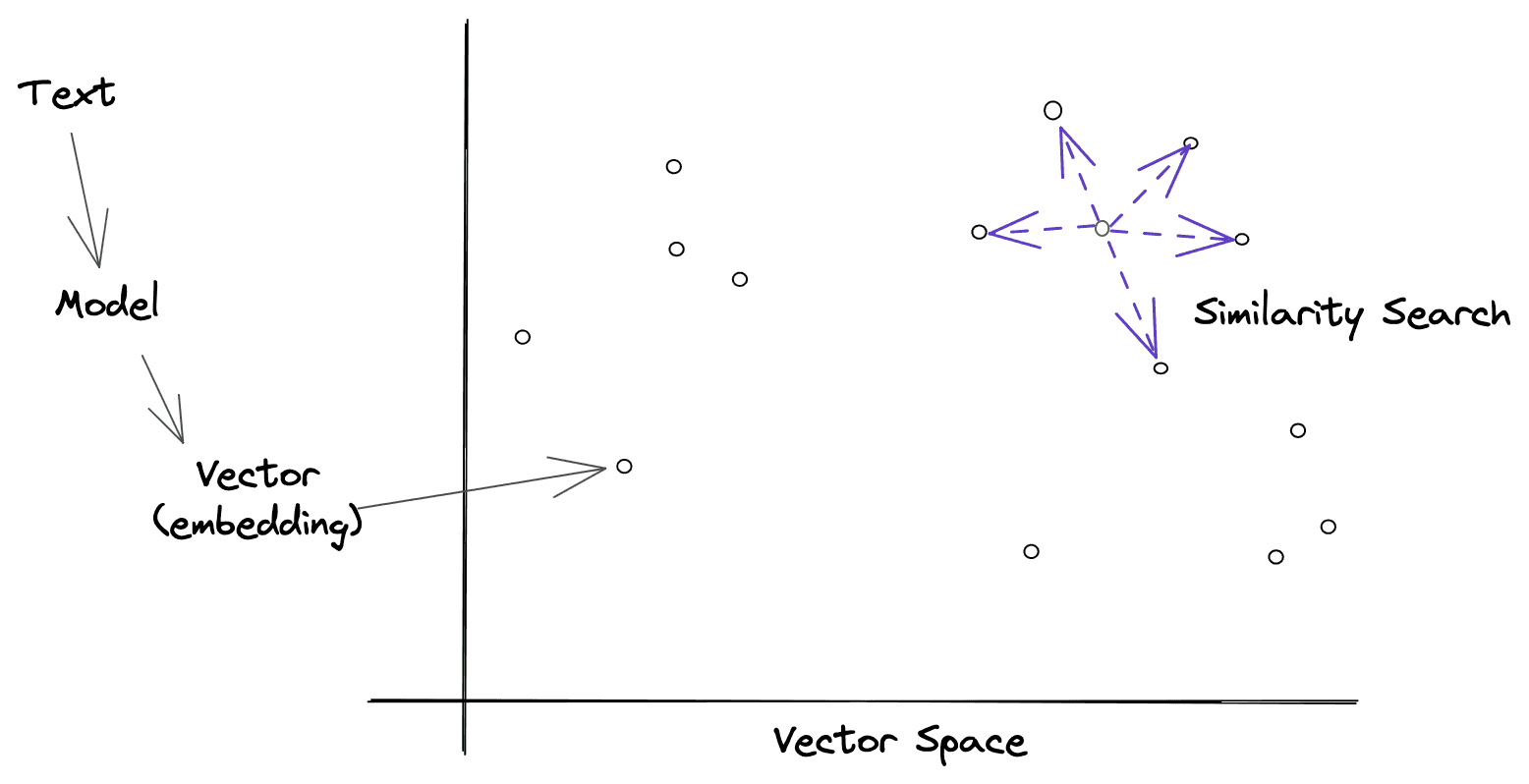
Semantic Search
In Retrieval-Augmented Generation (RAG) applications, vector databases power semantic search by representing data as high-dimensional vectors that encapsulate meaning and context. Unlike traditional keyword-based search, semantic search leverages dense vector embeddings to identify similarities in data, even when different words or phrases convey the same concept.
This capability allows RAG systems to retrieve the most relevant information from your business's knowledge base, enabling responses that are both accurate and contextually aligned. Semantic search provides a streamlined and effective way to tailor large language model outputs to meet the specific needs of your business.
Unified LLM interface
Melting Face processes queries through a unified, data center-agnostic interface, automatically load-balancing your chosen LLM’s queries to the least expensive data center available.
Inference costs can vary significantly between data centers and fluctuate based on real-time capacity. Melting Face dynamically routes queries to optimize cost-efficiency, ensuring your inferences are processed at the lowest possible expense while maintaining minimal latency.
For applications requiring ultra-fast inference processing, dedicated data center processing options are also available, delivering exceptional speed and performance when needed.

Melting Face employs a chained LLM architecture to boost efficiency and reduce inference costs in RAG applications. LLM data processing is resource-intensive, with costs tied to the number of input and output tokens required for queries and responses.
To minimize these costs, Melting Face utilizes a tiered approach. Frequently asked questions are cached and processed by a lightweight LLM, significantly reducing token usage for repetitive queries. Only novel or complex questions are routed through more powerful (and costlier) LLMs to generate accurate responses, which are then cached for future use. This approach ensures optimal performance while keeping operational expenses under control.
Chained LLMs
